

Du möchtest mit Datenanalyse in Python starten? Dann solltest du die bekanntesten Python-Bibliotheken kennenlernen, die weltweit am häufigsten von Anfängern genutzt werden. Viele Einsteiger greifen zuerst zu diesen drei Bibliotheken:
NumPy unterstützt dich bei mathematischen Aufgaben und großen Datenmengen.
Pandas hilft dir beim Organisieren und Bearbeiten deiner Daten.
Matplotlib sorgt für anschauliche Diagramme.
Diese Bibliotheken bieten dir einfache Bedienung, Vielseitigkeit und eine sehr gute Dokumentation. Probiere sie aus und entdecke, wie leicht der Einstieg in die Datenanalyse sein kann!
Wichtige Erkenntnisse
Pandas, NumPy und Matplotlib sind ideale Bibliotheken für den Einstieg in die Datenanalyse mit Python. Sie helfen dir, Daten zu organisieren, zu berechnen und anschaulich darzustellen.
Seaborn und Plotly erleichtern die Erstellung von schönen und interaktiven Diagrammen, die deine Daten klar und spannend präsentieren.
SciPy, Scikit-learn und Statsmodels bieten dir erweiterte Werkzeuge für mathematische Analysen, maschinelles Lernen und klassische Statistik.
Nutze virtuelle Umgebungen und Tools wie Anaconda, um Python-Bibliotheken einfach und sicher zu installieren und zu verwalten.
Starte mit kleinen Projekten und nutze Online-Tutorials sowie Jupyter Notebooks, um Schritt für Schritt deine Fähigkeiten in der Datenanalyse zu verbessern.
1. Pandas
Überblick
Pandas ist eine der wichtigsten Python-Bibliotheken für Datenanalyse. Du kannst mit Pandas Daten aus verschiedenen Quellen wie CSV-Dateien, Excel-Tabellen oder Datenbanken laden. Die Bibliothek hilft dir, Daten in Tabellenform zu organisieren und zu bearbeiten. Viele Anfänger starten mit Pandas, weil die Funktionen leicht verständlich sind.
Funktionen
Mit Pandas kannst du viele Aufgaben erledigen:
Daten einlesen und speichern (z. B. aus CSV oder Excel)
Daten filtern und sortieren
Fehlende Werte erkennen und ersetzen
Spalten und Zeilen hinzufügen oder entfernen
Statistiken berechnen, wie Mittelwert oder Summe
Tipp: Du kannst mit Pandas auch große Datenmengen schnell bearbeiten. Das spart dir viel Zeit bei der Analyse.
Beispiele
Hier siehst du, wie du mit Pandas eine CSV-Datei lädst und die ersten Zeilen anzeigst:
import pandas as pd
# CSV-Datei laden
daten = pd.read_csv('beispiel.csv')
# Die ersten 5 Zeilen anzeigen
print(daten.head())
Du kannst auch Spalten auswählen oder Daten filtern:
# Nur die Spalte 'Name' anzeigen
print(daten['Name'])
# Zeilen mit Wert größer als 100 in der Spalte 'Wert'
print(daten[daten['Wert'] > 100])
Für Einsteiger
Du findest viele Tutorials und Beispiele zu Pandas im Internet. Die Dokumentation ist sehr ausführlich. Viele Aufgaben in der Datenanalyse lassen sich mit wenigen Zeilen lösen. Du solltest Pandas ausprobieren, wenn du mit Tabellen arbeitest oder Daten bereinigen möchtest. Zusammen mit anderen Python-Bibliotheken bildet Pandas die Grundlage für viele Projekte in der Datenanalyse.
2. NumPy
Überblick
NumPy ist die Grundlage für viele numerische Berechnungen in Python. Du kannst mit NumPy große Mengen an Zahlen einfach und schnell verarbeiten. Viele andere Python-Bibliotheken nutzen NumPy als Basis. Die Bibliothek arbeitet besonders effizient, weil sie in C geschrieben ist. Das macht sie schneller als viele andere Lösungen in Python.
NumPy bietet dir viele mathematische Funktionen. Du kannst damit zum Beispiel Mittelwerte, Summen oder Matrizen berechnen. Die Kombination aus Geschwindigkeit und vielen Funktionen macht NumPy sehr beliebt.
Funktionen
Mit NumPy kannst du:
Mehrdimensionale Arrays (z. B. Matrizen) erstellen und bearbeiten
Mathematische Operationen wie Addition, Multiplikation oder Division auf ganze Arrays anwenden
Statistische Werte wie Mittelwert, Standardabweichung oder Maximum berechnen
Zufallszahlen erzeugen
Arrays filtern und sortieren
Tipp: Nutze NumPy, wenn du mit großen Zahlenmengen oder Matrizen arbeitest. So sparst du viel Zeit und Rechenleistung.
Beispiele
Hier siehst du, wie du ein Array erstellst und einfache Berechnungen durchführst:
import numpy as np
# Ein Array mit Zahlen erstellen
zahlen = np.array([1, 2, 3, 4, 5])
# Das Array mit 2 multiplizieren
print(zahlen * 2)
# Den Mittelwert berechnen
print(np.mean(zahlen))
Du kannst auch zweidimensionale Arrays (Matrizen) nutzen:
matrix = np.array([[1, 2], [3, 4]])
print(matrix)
Für Einsteiger
NumPy eignet sich sehr gut für Anfänger. Die Syntax ist einfach und klar. Viele Tutorials und Beispiele helfen dir beim Einstieg. Du findest schnell Lösungen für typische Aufgaben in der Datenanalyse. Wenn du mit anderen Python-Bibliotheken arbeiten möchtest, solltest du NumPy zuerst kennenlernen. Es bildet die Basis für viele Projekte in der Datenanalyse.
3. Matplotlib
Überblick
Matplotlib ist die Standardbibliothek für Datenvisualisierung in Python. Du kannst mit Matplotlib viele verschiedene Diagramme erstellen. Die Bibliothek eignet sich besonders gut, wenn du deine Daten anschaulich darstellen möchtest. Viele Nutzer schätzen die Flexibilität von Matplotlib. Du kannst fast jede Art von Diagramm erzeugen, die du für deine Analyse brauchst. Im Vergleich zu anderen Python-Bibliotheken bietet Matplotlib die größte Vielfalt an Visualisierungsmöglichkeiten.
Funktionen
Mit Matplotlib hast du viele Werkzeuge zur Hand. Hier sind einige wichtige Funktionen:
Du kannst Streudiagramme (scatterplot) nutzen, um Beziehungen zwischen zwei Zahlenreihen zu zeigen.
Liniendiagramme (lineplot) helfen dir, Trends oder Entwicklungen über die Zeit darzustellen.
Balkendiagramme (barplot) eignen sich, um verschiedene Gruppen oder Häufigkeiten zu vergleichen.
Du kannst Achsen, Farben und Beschriftungen individuell anpassen.
Matplotlib unterstützt auch komplexere Diagrammtypen wie Histogramme, Kreisdiagramme oder 3D-Plots.
Tipp: Wenn du spezielle Anforderungen hast, kannst du mit Matplotlib fast jede Visualisierung umsetzen. Die Bibliothek ist sehr flexibel, aber manchmal brauchst du dafür etwas mehr Code.
Beispiele
Hier siehst du, wie du mit Matplotlib ein einfaches Liniendiagramm erstellst:
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
plt.plot(x, y)
plt.title('Einfaches Liniendiagramm')
plt.xlabel('X-Achse')
plt.ylabel('Y-Achse')
plt.show()
Du kannst auch ein Balkendiagramm erstellen:
plt.bar(['A', 'B', 'C'], [5, 7, 3])
plt.title('Balkendiagramm')
plt.show()
Für Einsteiger
Matplotlib eignet sich gut für Anfänger. Die Grundfunktionen lernst du schnell. Viele Tutorials und Beispiele helfen dir beim Einstieg. Du kannst mit wenigen Zeilen Code erste Diagramme erstellen. Wenn du später mehr Anpassungen brauchst, findest du in der Dokumentation viele Erklärungen. Matplotlib ist ein wichtiger Baustein, wenn du mit Python-Bibliotheken Daten visualisieren möchtest. Probiere verschiedene Diagrammtypen aus und entdecke, wie du deine Daten am besten präsentierst.
4. Seaborn
Überblick
Seaborn baut auf Matplotlib auf und macht die Erstellung von Diagrammen noch einfacher. Du kannst mit Seaborn schnell schöne und aussagekräftige Visualisierungen erstellen. Viele Nutzer finden die Bedienung von Seaborn benutzerfreundlicher als bei Matplotlib. Die Bibliothek bietet dir eine übersichtliche Oberfläche und optimierte Standardeinstellungen. Du brauchst weniger Code, um ansprechende Diagramme zu erzeugen. Seaborn eignet sich besonders gut für statische, publikationsreife Visualisierungen.
Tipp: Wenn du Wert auf ein einheitliches und modernes Design legst, hilft dir Seaborn mit eingebauten Farbpaletten und Stilvorlagen.
Funktionen
Mit Seaborn kannst du viele verschiedene Diagrammtypen erstellen. Die wichtigsten Funktionen sind:
Einfache Erstellung von statistischen Visualisierungen
Automatische Anpassung von Farben und Stilen
Unterstützung für komplexe Diagramme wie Heatmaps und Regressionsplots
Integration mit Pandas-Datenstrukturen
Nutzer berichten, dass Seaborn besonders praktisch ist, wenn du schnell Muster und Zusammenhänge in deinen Daten erkennen möchtest. Die Bibliothek vereinfacht viele Aufgaben, die mit Matplotlib mehr Aufwand bedeuten.
Beispiele
Hier siehst du, wie du mit Seaborn typische Diagramme erstellst:
import seaborn as sns
import pandas as pd
# Beispieldaten
daten = pd.DataFrame({
'Kategorie': ['A', 'B', 'C', 'A', 'B', 'C'],
'Wert': [5, 7, 3, 6, 8, 2]
})
# Balkendiagramm
sns.barplot(x='Kategorie', y='Wert', data=daten)
# Liniendiagramm
sns.lineplot(x='Kategorie', y='Wert', data=daten)
Mit Seaborn kannst du auch Heatmaps, Boxplots und Streudiagramme sehr einfach erstellen. Die Syntax bleibt dabei immer übersichtlich.
Für Einsteiger
Du findest viele Anleitungen und Beispiele zu Seaborn im Internet. Die einfache Syntax hilft dir, schnell erste Ergebnisse zu sehen. Viele Anfänger schätzen, dass sie mit wenig Code schöne Diagramme erzeugen können. Seaborn ist eine der beliebtesten Python-Bibliotheken für Visualisierungen. Wenn du Wert auf Klarheit und Design legst, solltest du Seaborn ausprobieren. Die Bibliothek eignet sich perfekt, um deine Daten anschaulich und verständlich darzustellen.
5. SciPy
Überblick
Mit SciPy erhältst du eine mächtige Erweiterung für deine Datenanalyse. SciPy ergänzt NumPy um viele wissenschaftliche und statistische Funktionen. Du kannst mit SciPy komplexe mathematische Aufgaben lösen, die in vielen Bereichen der Forschung und Technik wichtig sind. Besonders bei mathematischen Analysen und Optimierungen zeigt SciPy seine Stärken. Viele Python-Bibliotheken nutzen SciPy als Grundlage für weiterführende Berechnungen.
Funktionen
Mit SciPy stehen dir viele Werkzeuge zur Verfügung:
Nullstellenberechnung: Du findest Lösungen für Gleichungen, die du nicht direkt berechnen kannst.
Numerische Integration: Du kannst Flächen unter Kurven berechnen, auch wenn das Integral schwer zu lösen ist.
Diskrete Fourier-Analyse: Du zerlegst Signale in ihre Frequenzanteile, was in der Signalverarbeitung wichtig ist.
Optimierung: Du findest optimale Werte für Funktionen, zum Beispiel das Minimum oder Maximum.
Statistische Auswertungen: Du führst Hypothesentests und Wahrscheinlichkeitsberechnungen durch.
Hinweis: SciPy bietet dir viele Algorithmen, die in der Praxis zum Einsatz kommen. Du nutzt diese Methoden zum Beispiel in der Wettervorhersage, im Ingenieurwesen oder in der Finanzwelt.
Beispiele
Hier siehst du, wie du mit SciPy eine Nullstelle berechnest und eine numerische Integration durchführst:
from scipy import optimize, integrate
import numpy as np
# Nullstelle der Funktion f(x) = x^2 - 2
def f(x):
return x**2 - 2
nullstelle = optimize.bisect(f, 0, 2)
print("Nullstelle:", nullstelle)
# Numerische Integration der Funktion g(x) = x^2 von 0 bis 1
def g(x):
return x**2
fläche, fehler = integrate.quad(g, 0, 1)
print("Fläche unter der Kurve:", fläche)
Mit diesen Funktionen löst du Aufgaben, die in der Schule oft nur mit Näherungen behandelt werden.
Für Einsteiger
Du findest viele Anleitungen und Beispiele zu SciPy im Internet. Die Dokumentation erklärt die wichtigsten Funktionen Schritt für Schritt. Wenn du schon mit NumPy gearbeitet hast, gelingt dir der Einstieg in SciPy besonders leicht. SciPy eignet sich für dich, wenn du tiefer in mathematische Analysen einsteigen möchtest. Viele Python-Bibliotheken für Datenanalyse bauen auf SciPy auf. Probiere SciPy aus, um deine Kenntnisse zu erweitern und neue Methoden kennenzulernen.
6. Scikit-learn
Überblick
Scikit-learn ist die bekannteste Bibliothek für maschinelles Lernen in Python. Du kannst mit Scikit-learn viele Aufgaben im Bereich Machine Learning lösen. Die Bibliothek hilft dir, Muster in Daten zu erkennen und Vorhersagen zu treffen. Viele Anfänger nutzen Scikit-learn, weil sie eine klare Struktur und viele Beispiele bietet. Du findest in Scikit-learn Werkzeuge für Klassifikation, Regression und Clustering.
Funktionen
Mit Scikit-learn kannst du:
Daten in Trainings- und Testdaten aufteilen
Verschiedene Machine-Learning-Modelle nutzen, wie Entscheidungsbäume, lineare Regression oder k-Means-Clustering
Modelle trainieren und testen
Ergebnisse auswerten und vergleichen
Daten vorverarbeiten, zum Beispiel normalisieren oder kategorisieren
Tipp: Scikit-learn arbeitet gut mit anderen Python-Bibliotheken wie Pandas und NumPy zusammen. So kannst du Daten einfach vorbereiten und analysieren.
Beispiele
Hier siehst du, wie du mit Scikit-learn ein einfaches Modell für die Vorhersage erstellst:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# Beispieldaten laden
daten = load_iris()
X = daten.data
y = daten.target
# Daten aufteilen
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Modell erstellen und trainieren
modell = DecisionTreeClassifier()
modell.fit(X_train, y_train)
# Vorhersagen machen
vorhersagen = modell.predict(X_test)
print(vorhersagen)
Mit wenigen Zeilen Code kannst du eigene Modelle ausprobieren und testen.
Für Einsteiger
Scikit-learn eignet sich sehr gut für deinen Einstieg in das maschinelle Lernen. Die Dokumentation enthält viele Beispiele und Erklärungen. Du findest im Internet zahlreiche Tutorials, die dir Schritt für Schritt zeigen, wie du Modelle erstellst. Viele Python-Bibliotheken für Datenanalyse nutzen Scikit-learn als Grundlage für Machine Learning. Probiere einfache Projekte aus, um die wichtigsten Funktionen kennenzulernen. So verstehst du schnell, wie maschinelles Lernen mit Python funktioniert.
7. Statsmodels
Überblick
Statsmodels hilft dir, wenn du statistische Analysen in Python durchführen möchtest. Diese Bibliothek ist auf klassische Statistik spezialisiert. Du kannst mit Statsmodels viele Modelle nutzen, die in der Wissenschaft und Wirtschaft wichtig sind. Besonders bei linearen Regressionen und Zeitreihenanalysen zeigt Statsmodels seine Stärken. Viele Nutzer schätzen die umfangreichen Diagnose- und Auswertungsmöglichkeiten.
Funktionen
Mit Statsmodels stehen dir viele Werkzeuge zur Verfügung:
Generalisierte lineare Modelle (GLM) für verschiedene Zielverteilungen
Diskrete Wahlmodelle, zum Beispiel Logit-Modelle für Klassifikationsaufgaben
Zeitreihenmodelle wie ARIMA für Prognosen
Überlebenszeitanalyse für medizinische oder technische Daten
Multivariate Analyse für mehrere Zielgrößen
Generalisierte additive Modelle (GAM) für nichtlineare Zusammenhänge
Statsmodels bietet dir viele Diagnosefunktionen, Hypothesentests und Konfidenzintervalle. Du kannst verschiedene Standardfehler einstellen, zum Beispiel robuste Standardfehler bei Ausreißern.
Im Vergleich zu anderen Python-Bibliotheken wie scikit-learn konzentriert sich Statsmodels auf klassische Statistik und bietet dir mehr Möglichkeiten für Inferenz und Modellprüfung.
Beispiele
Hier siehst du, wie du eine lineare Regression mit Statsmodels durchführst:
import statsmodels.api as sm
import numpy as np
# Beispieldaten
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 5, 4, 5])
# Konstante hinzufügen
X = sm.add_constant(x)
# Modell erstellen und anpassen
modell = sm.OLS(y, X).fit()
# Zusammenfassung anzeigen
print(modell.summary())
Mit wenigen Zeilen Code erhältst du viele statistische Kennzahlen und Tests.
Für Einsteiger
Statsmodels eignet sich gut, wenn du Statistik mit Python lernen möchtest. Die Dokumentation erklärt die wichtigsten Modelle und Funktionen Schritt für Schritt. Viele Beispiele helfen dir beim Einstieg. Du kannst Statsmodels nutzen, wenn du klassische statistische Methoden anwenden willst. Die Bibliothek ergänzt andere Python-Bibliotheken und gibt dir viele Möglichkeiten für Analyse und Auswertung. Probiere Statsmodels aus, wenn du mehr über Statistik und Datenanalyse erfahren möchtest.
8. Plotly
Überblick
Plotly hilft dir, moderne und interaktive Visualisierungen zu erstellen. Du kannst mit Plotly Diagramme bauen, die du direkt mit der Maus bedienen kannst. Viele Nutzer schätzen, dass du in Diagramme hineinzoomen oder Werte mit der Maus anzeigen kannst. Plotly eignet sich besonders gut für Web-Anwendungen und Dashboards. Du kannst deine Ergebnisse nicht nur anschauen, sondern auch mit ihnen arbeiten.
Plotly hebt sich von anderen Tools ab, weil du nicht nur statische Bilder bekommst. Du kannst deine Daten lebendig machen und direkt im Browser präsentieren.
Funktionen
Mit Plotly stehen dir viele Möglichkeiten offen:
Erstelle interaktive Diagramme wie Linien-, Balken-, Streu- oder Kreisdiagramme.
Nutze Mouse-Over-Tooltips, um Werte direkt im Diagramm zu sehen.
Zoome in Bereiche hinein oder verschiebe die Ansicht mit der Maus.
Exportiere deine Grafiken als Bild oder HTML-Datei.
Entwickle eigene Dashboards mit Plotly Dash, auch ohne tiefe Webkenntnisse.
Kombiniere verschiedene Diagrammtypen in einem Dashboard.
Im Vergleich zu Matplotlib und Seaborn bietet Plotly dir:
Interaktive Funktionen wie Zoomen und Tooltips direkt nach dem Erstellen.
Unterstützung für mehrere Programmiersprachen.
Besonders geeignet für dynamische und webbasierte Darstellungen.
Beispiele
Hier siehst du, wie du mit Plotly ein interaktives Liniendiagramm erstellst:
import plotly.express as px
# Beispieldaten
daten = {'x': [1, 2, 3, 4, 5], 'y': [10, 15, 13, 17, 14]}
# Interaktives Liniendiagramm
fig = px.line(daten, x='x', y='y', title='Interaktives Liniendiagramm')
fig.show()
Mit Plotly Dash kannst du sogar komplette Dashboards bauen, die sich für Echtzeit-Daten eignen.
Für Einsteiger
Du kannst mit Plotly schnell starten. Viele Tutorials zeigen dir, wie du Diagramme erstellst und Dashboards baust. In der Praxis berichten Nutzer, dass du mit wenig Code komplexe und ansprechende Visualisierungen entwickelst. Plotly Dash hilft dir, Webanwendungen zu erstellen, ohne dass du ein Webprofi sein musst. Nach kurzer Einarbeitung kannst du eigene Dashboards für Schule, Studium oder Beruf bauen. Besonders für Projekte mit Echtzeitdaten oder interaktiven Elementen ist Plotly eine sehr gute Wahl.
Tipps zu Python-Bibliotheken
Installation
Du möchtest Python-Bibliotheken installieren? Es gibt verschiedene Methoden, die dir helfen, schnell und sicher zu starten. Die folgende Tabelle zeigt dir die wichtigsten Wege und ihre Vorteile:
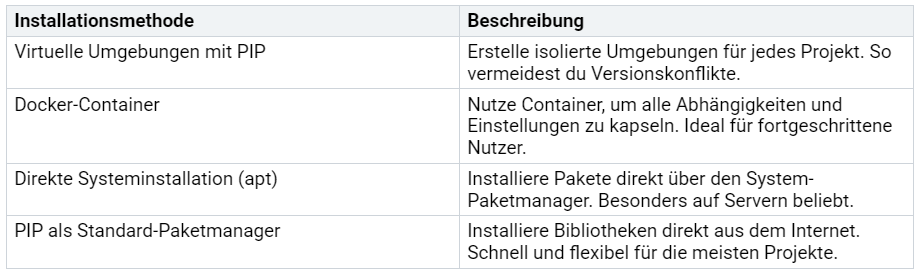
Tipp: Virtuelle Umgebungen schützen dich vor Versionsproblemen. Mit
python -m venv meinprojektstartest du ganz einfach.
Bei der Installation können manchmal Fehler auftreten. Die nächste Tabelle zeigt dir typische Probleme und wie du sie löst:
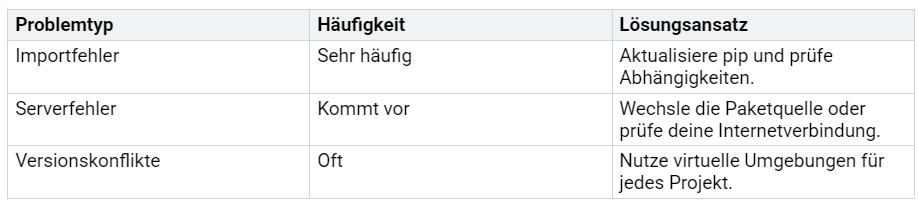
Viele Anfänger berichten, dass Anaconda den Einstieg erleichtert. Anaconda installiert viele Pakete automatisch und bietet mit dem Navigator eine grafische Oberfläche. So sparst du Zeit und vermeidest viele typische Fehler.
Ressourcen
Du findest im Internet viele kostenlose Lernangebote. Die folgende Liste hilft dir beim Einstieg:
Online-Tutorials: Seiten wie W3Schools, Real Python und FreeCodeCamp bieten dir Schritt-für-Schritt-Anleitungen.
Online-Kurse: Plattformen wie Coursera, Udemy und edX bieten strukturierte Kurse für Anfänger.
Übungsplattformen: Auf HackerRank, LeetCode und Codewars kannst du dein Wissen mit Aufgaben testen.
Community und Foren: In Foren wie Stack Overflow oder Reddit helfen dir erfahrene Nutzer bei Fragen.
Jupyter Notebooks: Diese Umgebung eignet sich besonders gut für Datenanalyse und Visualisierung.
Hinweis: Die große Python-Community sorgt für viele aktuelle Tutorials und schnelle Hilfe bei Problemen.
Einstieg
Starte mit kleinen Projekten, um die Grundlagen zu üben. Viele Anfänger bauen zuerst einen Taschenrechner. Dieses Projekt zeigt dir, wie Variablen, Funktionen und Kontrollstrukturen funktionieren. Du kannst es leicht erweitern und so dein Wissen festigen.
Weitere beliebte Projekte für den Einstieg:
Analysiere eine kleine CSV-Datei mit Pandas.
Erstelle ein einfaches Diagramm mit Matplotlib.
Nutze NumPy, um Zahlen zu berechnen.
Wähle ein Thema, das dich interessiert. So bleibst du motiviert und lernst schneller. Nutze Entwicklungsumgebungen wie Anaconda mit Jupyter Notebook oder Visual Studio Code. Diese Tools helfen dir, den Überblick zu behalten und Fehler schnell zu finden.
Du profitierst als Einsteiger von einer niedrigen Einstiegshürde und einer klaren, verständlichen Struktur. Nutzer loben die einfache Bedienung und die schnelle Umsetzung erster Projekte. Viele empfehlen folgende nächste Schritte:
Probiere kleine Datenanalysen mit Pandas oder NumPy.
Erstelle eigene Visualisierungen mit Matplotlib oder Seaborn.
Nutze Jupyter Notebooks für interaktives Lernen.
Viele Kurse und Tutorials helfen dir, dein Wissen zu vertiefen und neue Methoden zu entdecken.
FAQ
Welche Bibliothek eignet sich am besten für den Einstieg?
Du startest am besten mit Pandas. Die Bibliothek ist leicht zu verstehen. Viele Beispiele helfen dir beim Lernen. Pandas unterstützt dich bei den wichtigsten Aufgaben der Datenanalyse.
Muss ich alle Bibliotheken gleichzeitig lernen?
Du lernst am besten eine Bibliothek nach der anderen. Beginne mit Pandas oder NumPy. Später probierst du Matplotlib oder Seaborn aus. Schritt für Schritt verstehst du die Zusammenhänge besser.
Wie installiere ich eine Python-Bibliothek?
Du nutzt den Befehl pip install bibliotheksname im Terminal. Viele Anfänger verwenden auch Anaconda. Damit installierst du mehrere Bibliotheken auf einmal.
Kann ich die Bibliotheken auch ohne Programmiererfahrung nutzen?
Ja! Viele Bibliotheken bieten einfache Beispiele. Du findest viele Schritt-für-Schritt-Anleitungen. Mit etwas Übung verstehst du schnell die wichtigsten Funktionen.
Welche Bibliothek hilft mir bei Visualisierungen?
Du nutzt Matplotlib oder Seaborn für Diagramme. Plotly eignet sich für interaktive Grafiken. Jede Bibliothek hat eigene Stärken. Probiere verschiedene aus, um deinen Favoriten zu finden.