

Künstliche Intelligenz benötigt große Mengen an hochwertigen Daten, um Muster zu erkennen und fundierte Entscheidungen zu treffen. Die Qualität der Daten entscheidet über den Erfolg, denn unvollständige oder fehlerhafte Daten führen zu schlechten Ergebnissen. Verschiedene Anwendungsfälle verlangen unterschiedliche Datentypen. Zum Beispiel arbeitet klassisches Machine Learning oft mit strukturierten Daten, während Deep Learning auch unstrukturierte Daten wie Bilder oder Texte nutzt.
Wichtige Erkenntnisse
Künstliche Intelligenz braucht hochwertige und vielfältige Daten, um zuverlässig zu funktionieren und gute Ergebnisse zu liefern.
Strukturierte Daten sind klar geordnet und leicht zu analysieren, während unstrukturierte Daten wie Bilder und Texte wichtige zusätzliche Informationen liefern.
Eine breite und repräsentative Datenbasis verhindert Fehler und Verzerrungen, damit KI-Modelle auch in neuen Situationen gut arbeiten.
Datenschutz ist wichtig: Persönliche Daten müssen geschützt und gesetzliche Regeln eingehalten werden, um Vertrauen zu sichern.
Gute Datenpflege und sorgfältige Vorbereitung sind entscheidend, damit KI-Systeme genau und stabil bleiben.
Datenarten für Künstliche Intelligenz
Künstliche Intelligenz verarbeitet verschiedene Arten von Daten, abhängig vom jeweiligen Anwendungsfall. In der Praxis kommen strukturierte und unstrukturierte Daten zum Einsatz. Jede Datenart bringt eigene Herausforderungen und Vorteile mit sich. Unternehmen und Organisationen wählen die passende Datenart, um optimale Ergebnisse zu erzielen.
Strukturierte Daten
Strukturierte Daten liegen in klar definierten Formaten vor. Tabellen, Datenbanken und Listen gehören zu den bekanntesten Beispielen. Diese Daten lassen sich leicht durchsuchen und analysieren. In der Industrie erfassen Sensoren regelmäßig Messwerte wie Temperatur, Druck oder Geschwindigkeit. Diese Werte speichern Maschinen in Datenbanken. Künstliche Intelligenz nutzt diese strukturierten Daten, um Produktionsprozesse zu überwachen und Fehler frühzeitig zu erkennen.
Auch in der Medizin spielen strukturierte Daten eine wichtige Rolle. Patientendaten, Laborwerte und Medikationspläne werden in elektronischen Systemen gespeichert. Forscher wenden mathematische und statistische Methoden an, um die Qualität dieser Daten zu prüfen. Sie entwickeln standardisierte Kreuzvalidierungsstrategien, um Biomarker zu identifizieren. Diese Methoden belegen, dass strukturierte Daten für medizinische KI-Anwendungen unverzichtbar sind.
Im Handel analysieren Unternehmen Verkaufszahlen, Lagerbestände und Kundendaten. Diese Informationen liegen meist in Tabellenform vor. Künstliche Intelligenz erkennt darin Muster und hilft, das Sortiment zu optimieren.
Strukturierte Daten bieten eine solide Grundlage für viele KI-Anwendungen, da sie leicht zugänglich und auswertbar sind.
Unstrukturierte Daten
Unstrukturierte Daten besitzen kein festes Format. Dazu zählen Texte, Bilder, Videos und Audiodateien. Künstliche Intelligenz kann diese Datenarten verarbeiten, um neue Erkenntnisse zu gewinnen. In der Medizin analysieren KI-Systeme Röntgenbilder oder Arztberichte, um Diagnosen zu unterstützen. Im Handel werten Unternehmen Kundenbewertungen, E-Mails oder Social-Media-Beiträge aus. So erkennen sie Trends und verbessern den Kundenservice.
In der Industrie entstehen unstrukturierte Daten durch Maschinenprotokolle, Wartungsberichte oder Fotos von Anlagen. KI-Modelle durchsuchen diese Daten, um Anomalien zu entdecken und Wartungsbedarf vorherzusagen.
Die Wirtschaftsprüfungsbranche steht vor einer besonderen Herausforderung. Unternehmen erzeugen täglich Millionen digitaler Transaktionen. Komplexe Rechnungslegungsstandards und branchenspezifische Vorschriften erhöhen die Vielfalt der benötigten Datenarten. Manuelle Prüfungen reichen nicht mehr aus. Künstliche Intelligenz analysiert große und heterogene Datenmengen systematisch und effizient.
Beispiele für unstrukturierte Daten:
Bilder von medizinischen Untersuchungen
Freitext in Arztberichten
Kundenrezensionen im Online-Handel
Maschinenprotokolle in der Industrie
Künstliche Intelligenz benötigt sowohl strukturierte als auch unstrukturierte Daten, um in verschiedenen Branchen erfolgreich zu arbeiten. Die Auswahl der richtigen Datenart hängt immer vom Ziel und vom Anwendungsbereich ab.
Datenqualität für Künstliche Intelligenz
Qualität und Vielfalt
Hochwertige Daten bilden das Fundament für präzise KI-Modelle. Nur mit sauberen, vollständigen und aktuellen Informationen kann Künstliche Intelligenz zuverlässige Ergebnisse liefern. Verschiedene Quellen und Formate erhöhen die Vielfalt der Daten. Diese Vielfalt hilft, Muster besser zu erkennen und auf neue Situationen zu reagieren.
KI-Modelle analysieren große und vielfältige Datenmengen, um Zusammenhänge zu entdecken.
Die Menge und Relevanz der Daten beeinflussen direkt die Leistungsfähigkeit der Modelle.
Data Engineering sorgt dafür, dass Daten aus unterschiedlichen Quellen gesammelt, bereinigt und angepasst werden.
Standardisierte und harmonisierte Datenräume erleichtern die Integration und verbessern die Reproduzierbarkeit von Ergebnissen.
Kontinuierliches Lernen aus aktuellen Daten ermöglicht es KI-Systemen, sich an neue Herausforderungen anzupassen.
Im Umweltmanagement zeigen aktuelle und vielfältige Daten, wie Künstliche Intelligenz Naturkatastrophen erkennen oder Umweltauswirkungen messen kann.
Für viele Anwendungen gelten Mindestanforderungen. Ein KI-Modell benötigt eine ausreichende Datenhistorie und genügend Datenpunkte, um zuverlässig zu funktionieren. Fehlen diese, sinkt die Genauigkeit der Vorhersagen.
Tipp: Unternehmen sollten regelmäßig prüfen, ob ihre Daten aktuell und vielfältig genug sind, um die gewünschten Ergebnisse zu erzielen.
Repräsentativität
Repräsentative Daten spiegeln die Realität des Anwendungsbereichs wider. Nur so kann Künstliche Intelligenz verlässliche Entscheidungen treffen. Wenn ein Datensatz bestimmte Gruppen oder Situationen nicht abbildet, entstehen Verzerrungen. Diese Verzerrungen führen zu fehlerhaften Ergebnissen und können ganze Projekte gefährden.
Ein Beispiel: Ein medizinisches KI-System, das nur Daten von Erwachsenen nutzt, erkennt Krankheiten bei Kindern schlechter. Im Handel kann ein Modell, das nur Daten aus einer Region enthält, keine globalen Trends vorhersagen. Deshalb achten Unternehmen darauf, dass ihre Daten alle relevanten Gruppen und Szenarien abdecken.
Eine breite Datenbasis sorgt dafür, dass KI-Modelle auch in unbekannten Situationen stabil bleiben. Sie lernen, Unterschiede zu erkennen und flexibel zu reagieren.
Datenschutz
Datenschutz spielt bei der Nutzung von Daten für Künstliche Intelligenz eine zentrale Rolle. Unternehmen müssen sicherstellen, dass sie persönliche Informationen schützen und gesetzliche Vorgaben einhalten. Die Datenschutz-Grundverordnung (DSGVO) schreibt vor, wie personenbezogene Daten verarbeitet werden dürfen.
Daten sollten anonymisiert oder pseudonymisiert werden, bevor sie in KI-Projekten zum Einsatz kommen. So bleibt die Privatsphäre der Betroffenen gewahrt. Unternehmen dokumentieren, wie sie Daten sammeln, speichern und nutzen. Sie informieren Nutzer transparent über den Umgang mit ihren Daten.
Hinweis: Verstöße gegen Datenschutzregeln können hohe Strafen nach sich ziehen und das Vertrauen der Kunden dauerhaft schädigen.
Eine verantwortungsvolle Datenstrategie verbindet hohe Qualität, Vielfalt und Datenschutz. Nur so kann Künstliche Intelligenz ihr volles Potenzial entfalten und gleichzeitig ethische Standards wahren.
Datensammlung und Aufbereitung
Datenquellen
Viele Projekte im Bereich Künstliche Intelligenz beginnen mit der Suche nach geeigneten Datenquellen. Forschende und Unternehmen greifen auf Plattformen wie kaggle.com, ourworldindata.org oder Github zurück. Dort finden sie große, statistisch belegte Datensätze. Häufig entstehen eigene Datensätze durch Umfragen, Sensoren oder die Zusammenarbeit mit Organisationen. Der Bundeswettbewerb Künstliche Intelligenz zeigt, wie Teams Datensätze suchen, erstellen und prüfen. Sie beziehen oft Freunde, Familie oder Partner ein, um die Datenbasis zu erweitern.
Tipp: Eine breite Datenbasis verbessert die Aussagekraft von KI-Modellen und erhöht die Chancen auf zuverlässige Ergebnisse.
Datenbereinigung
Die Qualität der Daten entscheidet über den Erfolg von Künstliche Intelligenz. Data Science nutzt Methoden aus Statistik und Informatik, um Fehlerquellen frühzeitig zu erkennen. Die Datenbereinigung umfasst mehrere Schritte:
Entfernen von Ausreißern, die das Ergebnis verfälschen könnten
Standardisierung der Werte, damit alle Daten vergleichbar sind
Reduktion der Dimensionen, zum Beispiel mit der Hauptkomponentenanalyse (PCA)
Kategorisierung und Prüfung der Daten auf Vollständigkeit
In realen Projekten nimmt die Datenaufbereitung oft 30% der gesamten Projektzeit ein. Plattformen wie Microsoft Azure Machine Learning unterstützen den gesamten Prozess von der Bereinigung bis zur Modellierung.
Datenmanagement
Ein gutes Datenmanagement sorgt dafür, dass alle Daten sicher gespeichert und leicht zugänglich bleiben. Unternehmen dokumentieren, wie sie Daten sammeln, speichern und nutzen. Sie achten darauf, dass die Daten aktuell und korrekt sind. Data Science spielt eine zentrale Rolle: Sie prüft die Daten regelmäßig und harmonisiert verschiedene Quellen. So entstehen einheitliche Datenräume, die Künstliche Intelligenz optimal nutzen kann.
Hinweis: Sorgfältiges Datenmanagement schützt vor Fehlern und erleichtert die spätere Analyse.
Herausforderungen
Datenmangel
Viele Unternehmen stehen vor dem Problem, nicht genügend Daten für Künstliche Intelligenz zu besitzen. Ohne ausreichend große und vielfältige Datensätze kann ein Modell keine zuverlässigen Muster erkennen. Besonders in neuen Anwendungsbereichen fehlen oft historische Daten. Kleine Datensätze führen dazu, dass Modelle wichtige Zusammenhänge übersehen. Sie können dann keine guten Vorhersagen treffen. Auch die Ähnlichkeit zwischen Trainingsdaten und echten Anwendungsdaten spielt eine große Rolle. Wenn sich die Daten im Alltag stark von den Trainingsdaten unterscheiden, sinkt die Genauigkeit der Ergebnisse deutlich.
Tipp: Unternehmen sollten regelmäßig prüfen, ob ihre Trainingsdaten die Realität im späteren Einsatz widerspiegeln. Nur so bleibt die Leistung der Modelle stabil.
Fehlerquellen
Fehler in Datensätzen stellen eine der größten Herausforderungen für Künstliche Intelligenz dar. Verzerrte Daten, unvollständige Informationen oder eine schlechte Vorbereitung wirken sich direkt auf die Modellgenauigkeit aus. Die folgende Tabelle zeigt typische Fehlerquellen und deren Auswirkungen:

Ein Modell, das auf verzerrten Daten trainiert wurde, liefert oft unzuverlässige Ergebnisse. Es kann Probleme nicht effektiv lösen. Fachleute nutzen analytische Metriken wie Präzision, Recall, F1-Score und Mean Squared Error, um Fehlerquellen zu erkennen und die Genauigkeit zu bewerten. Sie sammeln große Datenmengen, bereinigen und validieren diese sorgfältig. Nur so lassen sich Fehlerquellen minimieren und die Leistung der Modelle sichern.
Hinweis: Sorgfältige Datenaufbereitung und kontinuierliche Überprüfung sind entscheidend, um Fehlerquellen frühzeitig zu erkennen und die Zuverlässigkeit von Künstliche Intelligenz zu gewährleisten.
Praxisbeispiele
Medizin
Im Gesundheitswesen nutzen Ärzte und Forscher viele verschiedene Datenarten. Sie arbeiten mit strukturierten Daten wie Laborwerten, Patientendaten und Medikationsplänen. Auch unstrukturierte Daten wie Röntgenbilder, MRT-Scans oder Arztberichte spielen eine wichtige Rolle. Künstliche Intelligenz hilft, Krankheiten schneller zu erkennen. Ein KI-System kann zum Beispiel Hautkrebs auf Fotos von Muttermalen erkennen. In Krankenhäusern analysieren Algorithmen große Mengen an Patientendaten, um Risiken für Komplikationen frühzeitig zu entdecken. So verbessert sich die Behandlung und Patienten erhalten schneller die richtige Therapie.
Handel
Im Handel setzen Unternehmen auf Daten, um bessere Entscheidungen zu treffen. Sie sammeln historische Verkaufszahlen, Kundenprofile und Wettbewerbsdaten. Diese Informationen helfen, das Sortiment zu optimieren und die Nachfrage vorherzusagen. Künstliche Intelligenz analysiert diese Daten und unterstützt bei der Preisgestaltung oder bei Produktempfehlungen. Das Unternehmen Bonprix steigerte die Verkäufe um 5 %, indem es Kundendaten mit Google AI auswertete. Dynamische Preise führten zu einer Umsatzsteigerung von 3 bis 10 %. Empfehlungen erhöhten die Verkaufszahlen sogar um 20 %. Die folgende Tabelle zeigt weitere Verbesserungen durch den Einsatz von KI im Handel:
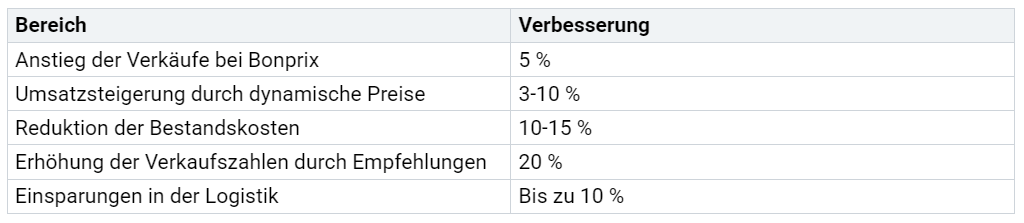
Unternehmen profitieren von gezielten Analysen und können schneller auf Marktveränderungen reagieren.
Industrie
In der Industrie erfassen Sensoren laufend Daten zu Temperatur, Druck oder Vibrationen. Maschinen liefern strukturierte Daten, die in Datenbanken gespeichert werden. Unstrukturierte Daten wie Wartungsberichte oder Fotos von Anlagen ergänzen diese Informationen. Künstliche Intelligenz erkennt Muster in den Sensordaten und warnt frühzeitig vor Ausfällen. Ein Beispiel: In einer Fabrik meldet ein KI-System ungewöhnliche Vibrationen an einer Maschine. Techniker können sofort reagieren und teure Reparaturen vermeiden. So steigert die Industrie die Effizienz und senkt die Kosten.
Laut aktuellen Analysen profitieren Unternehmen von Künstliche Intelligenz nur, wenn sie auf hochwertige, vielfältige und repräsentative Daten setzen. Strukturierte, unstrukturierte und zeitliche Daten müssen gezielt optimiert werden. Ein effektives Datenmanagement, das auch Datenschutz und Integration verschiedener Quellen berücksichtigt, bleibt entscheidend.
Wer in Datenqualität und moderne Plattformen investiert, sichert sich Wettbewerbsvorteile.
Empfehlungen:
Daten regelmäßig prüfen und bereinigen
Vielfalt und Repräsentativität sicherstellen
Datenschutz konsequent beachten
FAQ
Welche Datenmenge benötigt Künstliche Intelligenz?
Die benötigte Datenmenge hängt vom Anwendungsfall ab. Für Deep Learning sind oft Millionen Datenpunkte nötig. Klassisches Machine Learning kommt mit weniger aus. Mehr Daten verbessern meist die Genauigkeit, aber auch die Qualität zählt.
Wie erkennt man gute Datenqualität?
Gute Daten sind vollständig, aktuell und korrekt. Sie enthalten keine Fehler oder Ausreißer. Experten prüfen die Daten regelmäßig und nutzen statistische Methoden.
Tipp: Ein Daten-Check vor jedem KI-Projekt spart Zeit und Kosten.
Warum ist Repräsentativität bei Daten wichtig?
Repräsentative Daten spiegeln die Realität wider. Sie verhindern Verzerrungen und sorgen für faire Ergebnisse. Fehlen bestimmte Gruppen, kann die KI falsche Schlüsse ziehen.
Beispiel: Ein Modell für Hautkrankheiten muss verschiedene Hauttypen enthalten.
Welche Rolle spielt Datenschutz bei KI-Projekten?
Datenschutz schützt persönliche Informationen. Unternehmen anonymisieren oder pseudonymisieren Daten. Sie halten sich an Gesetze wie die DSGVO.
VorteilBeschreibungVertrauenNutzer fühlen sich sicherRechtssicherheitUnternehmen vermeiden Strafen
Können Unternehmen öffentliche Datenquellen für KI nutzen?
Viele Unternehmen greifen auf offene Datenquellen zurück. Plattformen wie Kaggle oder Open Data Portale bieten große Datensätze.
Achtung: Die Nutzung muss mit den jeweiligen Lizenzbedingungen und Datenschutzregeln übereinstimmen.